
Derin Yapay Sinir Ağları ile insan tipi deneme yanılmayla öğrenme biçimi olan Pekiştirmeli Öğrenme’yi birleştirerek son 3–5 yıldır bütün dünyada büyük heyecan uyandıran trene, biz de KoçDigital bünyesinde geçen yıl kurduğumuz Ar-Ge grubuyla bindik ve otomotiv sanayiinden finans sektörüne uzanan bir yelpazede Türkiye’nin lider kurumlarıyla Derin Pekiştirmeli Öğrenme projeleri oluşturmak için çalışmaya başladık. Geçen bir yılın sonunda, konudaki Türkçe kaynaklar bakımından bakirliği de yavaş yavaş değiştirmemiz gerektiğini anladık ve bu nedenle KoçDigital blog sayfasında Derin Pekiştirmeli Öğrenmeye yönelik çeşitli seviyelerde eğitici yazılar yayımlama kararı aldık. Okumakta olduğunuz yazı da, bu kararımızın ilk meyvesidir. İyi ve her şeyden önce, eğlenceli okumalar dileriz.
Yapay zeka (YZ) her ne kadar son yirmi yılın popüler kavramı olsa da, YZ’nin kültürümüzdeki yolculuğu, farklı biçimlerde binlerce yıldır sürüyor. Topal tanrı Vulkan’ın Krete’yi koruması için yarattığı bronz dev Talos ile bir hayal,
bir efsane olarak başlayan bu serüven, arada talihsiz bir biçimde mekanik türk adıyla anılan santranç otomatı ile dolambaçlı yollara sapsa da, geçen yüzyıl atılan teorik ve pratik temellerle yavaş yavaş düzenbazların oyun alanı olmaktan çıktı.

Bugün artık pasaport kontrollerinde kimin geçip kimin geçmeyeceğine karar veren yüz tanıma sistemlerinden tutun, hangi filmi seveceğimizi söyleyen öneri sistemlerine kadar pek çok YZ uygulaması hayatımızın bir parçası. Örnekler bunlarla sınırlı değil elbette, müşteri segmentasyonu, hava durumu tahmini, ve sigorta sahteciliği gibi pek çok sorun artık YZ yardımıyla çözülüyor. Ancak açık konuşalım, çok faydalı olsalar da bunlar hayalini kurduğumuz Talos gibi artistik değil; zeki ya da insansı dediğimizde kafamızda canlandırdığımız (Ben Robot, R2D2, hatta hatta Discovery One) örneklere hiç benzemiyor. Ama karamsarlığa gerek yok, bu yazının başlığında adı geçen YZ yöntemi Derin Pekiştirmeli Öğrenme (DPÖ) ile işin rengi değişmeye başlıyor. Biz de bu yazımızda, dünyada da ancak son üç beş yıldır yavaş yavaş uygulama alanları bulmaya başlayan Derin Pekiştirmeli Öğrenme yöntemine hızlı bir giriş yapacağız. Takip eden yazımızda ise, Deep Mind’tan bir grubun yazdığı Nature makalesi Human-level control through deep reinforcement learning’de geliştirilmiş DQN tekniğiyle kendi başına atari oynamayı öğrenen bir program yazacağız. İlerleyen zamanlarda ise, bir yandan teorik temellerin anlatıldığı yazılar yayınlarken öte yandan da iş dünyasındaki Derin Pekiştirmeli Öğrenme örneklerini inceleyeceğiz.
İşe, kısa bir soruyla başlayıp, sonra da terminolojimizi oluşturalım:
Soru: Pekiştirmeli Öğrenme nedir?
Yanıt: Pekiştirmeli Öğrenme, akıllı biçimde karar alıp uygulayan, uygulanan kararın sonucuna göre yeni bir karar alan ve bu şekilde devam eden sistemler yaratmaya yarayan bir makine öğrenmesi dalıdır.
Bu yanıtın ışığında terminolojimizi oluşturalım: …
PÖ ajanı (agent): Eğitim süreci sonunda otonom şekilde karar vermesini istediğimiz şey. Bu, satranç oynamayı öğrenen bir program, yürümeyi öğrenen bir robot, müşterilerin borsada alacakları kağıtlar konusunda anlık önerilerde bulunan sanal bir yatırım uzmanı ya da sanal bir atari oyuncusu olabilir.
PÖ durumu (state): PÖ ajanının içinde bulunduğu, onu ilgilendiren her şey. Durumların oluşturduğu topluluk literatürde S ile gösterilmektedir.
-
Satranç oynamayı öğrenen robot için durum, sıra kendisine geldiğinde tahtadaki pozisyon olabilir,
-
Yürümeyi öğrenen robot için durum, robotun algıladığı yüzey bilgisi (yükselik, eğim vs), ve ek olarak eklem yerlerinin açıları, ivmeleri vs olabilir.
-
Sanal yatırım uzmanı için durum, borsadaki kağıtların anlık bilgileri (belki dün ve önceki günkü bilgileri de dahil) ve öneri alan kişinin finansal bilgileri olabilir.
Üç örneğimizde de italik harflerle yazdığımız olabilir kelimesini de kısaca aydınlatmak gerekir. Buradaki olabilir kelimesinin işaret ettiği şey, durumu, PÖ sistemini kuranların, yani bizlerin belirleyeceğimiz olduğudur. Yani, aslında saha uzmanlığı da gerektiren, “acaba bu PÖ ajanının istenilen şeyleri yapabilmesi için neleri bilmek gerekir” sorusuna anlamlı yanıtlar verebilmek gerekmektedir.
PÖ eylemi (action): PÖ ajanının yapabilecekleri. Eylemlerin oluşturduğu topluluk literatürde A ile gösterilmektedir.
-
Satranç oynamayı öğrenen program için eylem, sıra kendisine geldiğinde yapabileceği geçerli hamlelerin her birisi,
-
Yürümeyi öğrenen robot için hangi eklemimi hangi yönde ve ne hızda döndüreyim sorusunun yanıtı,
-
Sanal yatırım uzmanı içinse, tipik bir eylem şu şekilde olabilir: X hissesinden şu kadar al/sat ya da bekle.
PÖ ödülü (reward): PÖ ödülü, ya da kısaca ödül, ajanın eylemleri sonucu, bizim ajana verdiğimiz sayısal bir geri besleme sinyali. Yukarıdaki örnekler için aday ödüllerin ne olabileceğine bakalım:
-
Sanal satranç oyuncumuzun hamlesinden sonra oyunu kazandıysa +1 puan, kaybettiyse 0 puan, berabere kaldıysa da +1/2 puan verilebilir.
-
Yürümeye çalışan robotumuz için, her eylemden sonra pozitif yöndeki ilerleme kadar puan verilebilir.
-
Sanal yatırımcımız için ödül biraz daha karmaşık olabilir. Biraz düşünelim. İyi bir yatırımcı nasıl olmalı? Müşterisi tarafından güvenilir olmalı. O halde eylem olarak müşteriye bir öneride bulunulduktan sonra her öneriden sonra: Eğer müşteri öneriyi dinlememişse ödül olarak negatif bir sayı verilebilir ki, güvenilirlik bir kıstas olsun. Dinlenilen bir öneriden sonra ise, tabii ki önerinin sonucu değerlendirilmeli.
PÖ politikası (policy): Politika’dan kasıt, ajanımızın karar verme mekanizması. Yani, ne zaman ne yapacağını belirleyen yöntem. Matematiksel anlamda politika durumlar kümesinden eylemler kümesine giden bir fonksiyondur. Buralarda bir matematikçi olsaydı bunu kısaca anlatmak için şöyle yazardı:
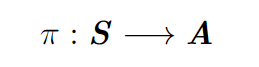
PÖ amacı (goal): Pekiştirmeli Öğrenmenin amacı, şahane politika bulmaktır. Yani, öyle bir politika bulmaktır ki, politikanın dediği yapılırsa uzun vadede toplanan ödüller olabildiğince yüksek olsun. Bu kavramın net bir açıklaması rassal değişkenler, istatistiki beklenti hesapları gibi bir dizi karmaşık terimin anlatılmasını gerektirdiği için bu yazıda bu işe hiç girişmeyeceğiz. Ama gelecekte SÖZ.
Gerekli terminolojimizi oluşturduk. Son olarak, Derin Öğrenme ile Pekiştirmeli Öğrenme’nin nasıl birleştiğine bakacağız. Ama Pekiştirmeli Öğrenme’yle ilgili giriş mahiyetindeki herhangi bir yazıda bulunmazsa yazara dayak yedirtecek olan, Pekiştirmeli Öğrenme paradigmasını özetleyen aşağıdaki resmi koymamak olmaz:
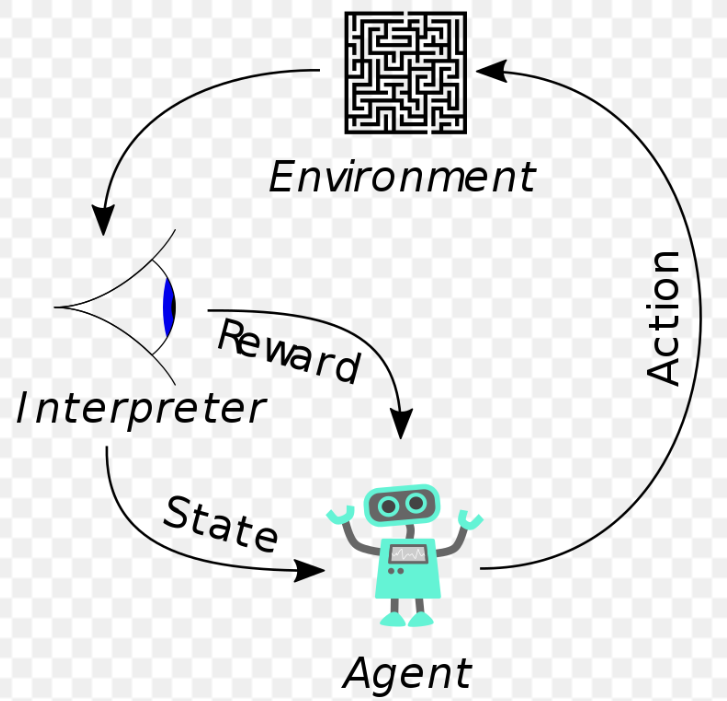
Resim diyor ki, ajan bir eylem belirler ve uygular, buna bağlı olarak hem durum değişir hem de ajan bir ödül alır. Ajan bir eylem belirler ve uygular, buna bağlı olarak…
Yazımızı bitirmeye hazırız. Evet, derin öğrenme nerede değil mi? Yukarıdaki resme ufak bir ekleme yapınca anlayacağız.

Bu resme, gelecek yazımızda, ay yüzeyine inmeyi kendi kendine öğrenen bir program yazarak anlam vereceğiz.